We receive all kinds of junk and old electronics at Tarrafa Hackerspace. One day, we received an Epson ActionPrinter 2000.

The ribbon was dry, but the printer still worked, so we bought a new ribbon and started having fun printing out ASCII-art stuff.
The ActionPrinter 2000 offers a few different kinds of fonts and modes: Draft, Near Letter Quality (Roman and Sans Serif), condensed mode, 12 characters per inch, 10 characters per inch, subscript, superscript… It occurred to me that the font used for the ASCII-art conversion programs was hardcoded, and probably didn’t relate to the one used in the ActionPrinter 2000.
So I was interested in mapping out the character bitmaps to get a better ASCII-art conversion. My first thought was: “let’s get a magnifying glass and map the characters dot by dot!”.

Sure, that worked, but it was time consuming and not the smartest way… There should be some better way. To print out the dots, at some point there must be an electrical signal being sent to the printhead for each dot. So, what if I intercepted that signal and used it to map out the characters?
I opened up the printer and looked for the printhead connector. But then I found a 27c256 EPROM inside, which likely contained the firmware. Hey, the firmware has all the characters inside it somewhere, that’s better than fiddling with the printhead. I got the 27c256’s datasheet and used an Arduino Mega to dump its contents.

After reading through the dump for quite some time, I found some bitstreams that looked like characters, but they weren’t very well organized, so I couldn’t make sense of their structure. Then I remembered that the last time I had visited Garoa Hackerspace, it was Retroprogramming night, and Felipe “Juca” Sanches was talking about emulating old hardware using MAME/MESS. Well, what if I emulated the firmware and recorded the data before it was sent to the printhead?
So I started fiddling around with MESS. It already had some incomplete drivers for the Epson LX-800 and Epson EX-800 printers. I used them as a basis to get my head around the MESS codebase and add support for the ActionPrinter 2000. It shouldn’t be so hard, right? (whenever I ask “right?”, the answer is “wrong”).
So I added the ActionPrinter 2000 firmware and fired up MESS. The processor hanged. I spent some time looking for buttons or switches being read by MESS, maybe just tweaking them would get past the hang. That wasn’t the case, it would still hang and there was no way out of it. Now, if only I had a debugger to see what was wrong… Oh, MESS has a debugger.
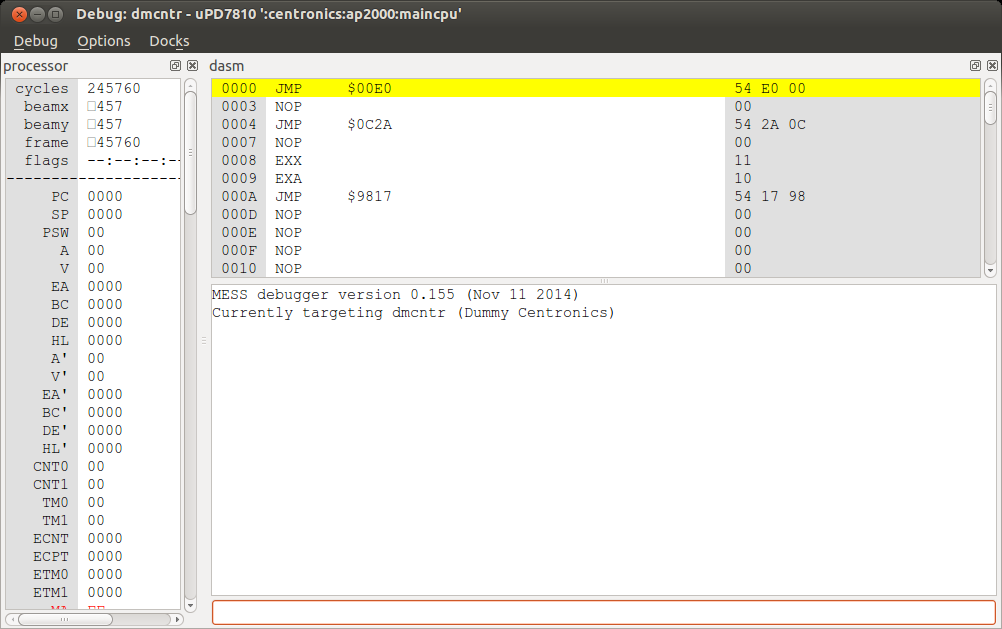
So, the ActionPrinter 2000 uses an uPD7810 processor. I needed to get its datasheet to understand the assembly. After stepping through the assembly for quite some time, I realized the uPD7810 emulation in MESS was lacking a few functions. There was no ADC support, which was necessary to read the input voltage and some switches. If the printer’s input voltage was too low, the printer would not boot.
So I implemented ADC support, and the firmware would just hang again a few instructions later. What was wrong this time? An interrupt wasn’t being set inside the processor. Who should be setting that interrupt?
I had already started reverse-engineering the printer’s hardware, but now I knew it was important to map all hardware connections in MESS. There were many other integrated circuits: a gate array (E05A30), a RAM chip (2064C), a 256-bit EEPROM (93c06), a stepper motor driver (SLA7020M), and others…
The gate array that was partly implemented in MESS was the E05A03, not the E05A30. It’s a custom-made gate array, and works pretty much like a black box. There’s no way to find out what goes on inside if you don’t have access to the datasheets (which I didn’t). I created some skeleton code for the E05A30 gate array for MESS.
I found out the interrupt that wasn’t being set should have been set by the gate array. So I added an interrupt request right after the gate array started.
I got a few more instructions being run and the firmware would hang again. At this point it was getting complicated having to read the assembly all the time, so I started manually decompiling the firmware. It is a 32 KB firmware. It shouldn’t take too long, right? (remember: the answer is “wrong”)
With a bit of decompiled code, I got this snippet:
void reset_ram(uint8_t val)
{
memset(0x9800, val, 0x2000);
if (*((uint8_t *)0xb7ff) != 0xff) {
killall();
beep(4, 2);
while(1); /* HANG */
}
}
void _start()
{
[...]
reset_ram(0xff);
reset_ram(0x00);
[...]
}
That didn’t make much sense to me. The RAM was only 8 KB, starting at 0x8000 and ending at 0xa000. There should be nothing at 0xB7FF. Even if there was something, it was being set to 0xFF and then to 0x00, but the data was expected to stay at 0xFF. It might be something inside the gate array, I don’t know. I just created a fake memory device that worked just as was expected for the emulator to be happy.
I got some more instructions, but it entered an infinite loop. Hey, that’s better than hanging…
After much more debugging and decompiling, I realized that the printer was outputting some commands to the gate array in a loop. There were 8 commands being sent and there would be a check for a sensor in the board. I looked at the sensor in the printer, and it turned out to be the Home sensor, i.e. whether the printhead was back at position 0. The command sequence being sent looked very familiar, like the phase signals for a stepper motor. MESS already had stepper motors implemented. I just needed to adapt the command sequence, because it passed through the SLA7020M before reaching the motor. And then I got this:
:__________@_______________________________:
:_________@________________________________:
:________@_________________________________:
:_______@__________________________________:
:______@___________________________________:
:_____@____________________________________:
:____@_____________________________________:
:___@______________________________________:
:__@_______________________________________:
:_@________________________________________:
:@_________________________________________:
:_@________________________________________:
:__@_______________________________________:
:___@______________________________________:
:____@_____________________________________:
:_____@____________________________________:
:______@___________________________________:
:_______@__________________________________:
:________@_________________________________:
:_________@________________________________:
:__________@_______________________________:
:___________@______________________________:
:____________@_____________________________:
:_____________@____________________________:
:______________@___________________________:
:_______________@__________________________:
:________________@_________________________:
:_________________@________________________:
:__________________@_______________________:
:___________________@______________________:
:____________________@_____________________:
This is a printf() of the motor seeking home and going back to the middle of the page. The printer was finally starting to work! This was awesome!
But then, the printer would get into an infinite loop again. It was waiting for the Online button to be pressed, but it wasn’t being acknowledged by the processor. That’s when I realized that the button should trigger an interrupt, which wasn’t properly implemented in MESS. So I implemented the interrupt properly and pressed the Online button.
According to the printer’s User Manual, now the printer should be pulling paper. Indeed, I noticed a different command sequence being sent (for the Paper Feed stepper motor). Now I had both motors working.
What was the next step? Entering the input loop. I should be able to send commands to the printer and have it print them out to paper.
At this moment we take a little pause. We need to realize that the work up to here has already taken me many months. It may seem simple when being read in a blog post, but it was a lot of hard work.
So, instead of going for the input loop, I decided to use the printer’s self-test function. While running the self-test function, I got more commands being sent to the gate array. I suspected they were the printhead signals (the ones I was after right when I started this). Indeed, they seemed like characters, but there was a problem: the printhead wasn’t being fired. After some debugging, I noticed that the timer which would fire the printhead was incorrectly implemented in MESS, so I had to fix that.
Finally, I had a bunch of stuff being printed. I wrote a little script to organize that stuff into an image, and then I got this:

I finally got my characters.
The code can be found in my GitHub account, inside the MAME repository and the lx810l branch. It should be merged into MAME upstreams in a few days. To run the self-test, build the dummy_centronics subtarget from the lx810l-debug branch.
By the way, the characters matched the ones I got with the magnifying glass…