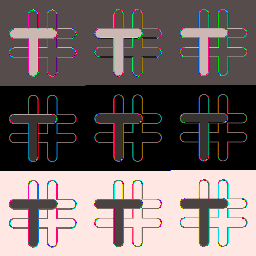Being a former FFmpeg developer myself, I remembered having made quite a bunch of experimentation with it, but it was mostly ephemeral and just for fun. Then I thought to myself: what about turning those bits and pieces of experimentation into blog posts and projects on GitHub?
And so the first project is born into my very new ffglitch repository. The name of the repository suggests more FFmpeg glitch art projects will come, and I hope my laziness doesn’t stop me from doing this (which it likely will).
The pix_fmt project consists of doing a whole bunch of incorrect pixel format conversions. If you don’t know what pixel formats are, read up on my previous blog post pixel formats 101.
The project is a script that generates a bunch of combinations for pixel format conversion. For example, one such conversion takes raw RGB data as input, pretends that data is YUV420p, and reconverts it to RGB. The project does this for all possible input to output pixel format combinations. This amounts to nearly 10000 images, with about 4000 being unique.
To try it out, just do:
$ git clone https://github.com/ramiropolla/ffglitch.git
$ cd pix_fmt
$ python pix_fmts.py <input.png> > makefile
$ make -r -k -jN
$ cd output_dir
$ fdupes --delete --noprompt .
What are the results like? Well, here are some samples (originals first):
How is an image represented in the computer’s memory?
There are a billion different file formats, codecs, and pixel formats that can be used for storing images. Think BMP, PNG, WEBP, BPG, GIF (pronounced JIF), lossy, lossless, whatever…
But at some point, the image is read from disk, demuxed, decompressed, and then we have a bunch of data in the computer’s memory. It is raw data. Just pixels. What is that raw representation of pixels like?
You’ve probably heard of RGB. The simplest answer could be:
First there’s a red pixel, then a green pixel, then a blue pixel, and so on and so on…
rgbrgbrgb
Great. Kind of. In that case, each pixel would be spread out through its three components, so we would have
one pixel, then another pixel, then another pixel, and so on and so on…
and for each of those pixels, we would have
one red component, then one green component, then one blue component.
pixel_rgbrgbrgb
But images are bidimensional. They are made up of many lines stacked one on top of the other. The computer’s memory is just one long line. Should we have one RAM stick for each line of our image?
Of course not, we just put the lines one next to the other. So now we have:
Pixel 1 from line 1, pixel 2 from line 1, …, pixel n from line 1, pixel 1 from line 2, pixel 2 from line 2, …, pixel n from line 2, …, …, …, …, pixel 1 from line m, pixel 2 from line m, …, pixel n from line m.
where n is the width of one line and m is the height of the image.
line_pixel_rgbrgbrgb
If each component for each pixel is 1 byte, then each pixel is 3 bytes, each line is n * 3 bytes, and the entire image is m * n * 3 bytes.
Now let’s see another pixel format: YUV. It is very widely used for lossy video codecs and lossy image compression because it can easily deal with the fact that our eyes perceive brightness better than color. Each pixel is transformed into one component for luminance (roughly equivalent to brightness), and two funky values describing color information. We will call those components Y (luminance), U and V (chrominance). Let’s suppose they’re also 1 byte for each component.
So, for this pixel format, we just do the same as with RGB, but storing the YUV components instead, right? Like so:
one Y component, then one U component, then one V component, and so on and so on…
line_pixel_yuvyuvyuv
Sure, we could, but that’s not normally what we do. Remember that our eyes are better at perceiving luminance than chrominance? What happens if we throw away half of the information related to chrominance? Well, we still get a pretty darn good looking image. What we have now is:
one Y component, then one U component, then another Y component, then one V component, and so on and so on…
line_pixel_yuyvyuyvyuyv
Remember that the RGB image used n * m * 3 bytes? The YUV image with half the color information thrown out will take n * m bytes for Y, and n * m for both U and V combined, for a total of n * m * 2 bytes. Heck, we just cut the image size by 33%!!! and it still looks good (search on google for image comparisons, I’m too lazy to make them myself). In the image above, even though it’s smaller, we now described 4 pixels per line instead of 3.
But that’s not all the fun we can get out of YUV. Suppose you have an old black and white film (actually, what we call black and white in this case is really grayscale. It’s not only 100% black or 100% white pixels. It will encompass many shades of grey between full black and full white).
So suppose you have a film with many shades of grey. There is no color information at all in there. Then why are we wasting precious disk space or precious memory with all three Y, U, and V components? We can just throw away U and V entirely and still have the exact same output on our screens. We just cut the image size by 66% in regards to the original image!!! What we have now is:
one Y component, another Y component, another Y component, and so on and so on…
line_pixel_yyyyyyyy
Now suppose you have a film that does have color, but some people watching it might be stuck with black and white TVs. Some viewers will get the colored stuff, other viewers only care about the Y. Therefore we HAVE to transmit Y, U, and V. But then, black and white TVs will have to sift through the data and select only the Y components. It will have to do:
get Y component, drop U component, get Y component, drop V component, get Y component, drop U component, get Y component, drop V component, and so on and so on…
line_pixel_yuyvyuyvyuyv_nouv
If only there was a way to sort the Y, U, and V data in a way that made it simpler to select each specific type of components… Oh, wait, there is a way! It’s called planar YUV. It’s all still the same data, but the way they’re represented in memory will look like:
plane 1: one Y component, another Y component, another Y component, and so on and so on…
plane 2: one U component, another U component, another U component, and so on and so on…
plane 3: one V component, another V component, another V component, and so on and so on…
line_pixel_planar_yuv
Now that black and white TV set can just get the Y plane, and then drop the entire U and V planes.
line_pixel_planar_yuv_nouv
There’s a shitload more of pixel formats around. There are higher bit-depths (9, 10, 16 bits per pixel, both in little-endian and big-endian), YUV with interleaved UV, paletted formats (remember old arcade consoles?), YUV formats that drop a bunch more color information (both horizontally and vertically), different component orders for RGB (i.e. BGR)… Just look at this list created by ffmpeg -pix_fmts:
That was a very very basic introduction about pixel formats. If you want to learn more about this, then you should go on and read the pixel format descriptors from the FFmpeg source code. Or else, if you’re not ready to spend a couple of years learning C and delving into the FFmpeg source code, just search on google. There is a bunch of information out there…